
Field‑to‑Product: an operating system for Forward‑Deployed Engineers
An operating system for FDEs: embed, upstream, and measure your way from field pain to product advantage.

Most AI deployments fail for the same reason: there is no error‑correction loop with reality. Code is written, a demo is shown, and the software is “done,” but nobody is embedded with the customer to observe how the product fails in the wild. Forward‑deployed engineers (FDEs) fix that. This post lays out an operating system for embedding FDEs so that deployments work by default.
Hypothesis and falsifiability
Hypothesis: When FDEs are embedded in customer workflows, they surface hard‑to‑vary explanations for failure, turn them into upstream changes, and shrink time‑to‑value across accounts.
How to falsify: If field work does not reduce bespoke maintenance and does not increase the share of field‑originated product improvements, then this hypothesis fails.
From demos to production
When teams build AI prototypes, success is often measured by the wow factor in a controlled environment. Real deployments, however, run on messy, live data and demand reliability, observability, and guardrails. Forward‑deployed engineers bridge this gap by taking promising demos through the additional steps required for safe, scalable production.

The field‑to‑product flywheel
FDEs operate a learning loop: They fix issues in the field and upstream the fix as a pull request (PR), which reduces bespoke work and accelerates reuse. Instead of firefighting the same problems in every account, knowledge compounds.
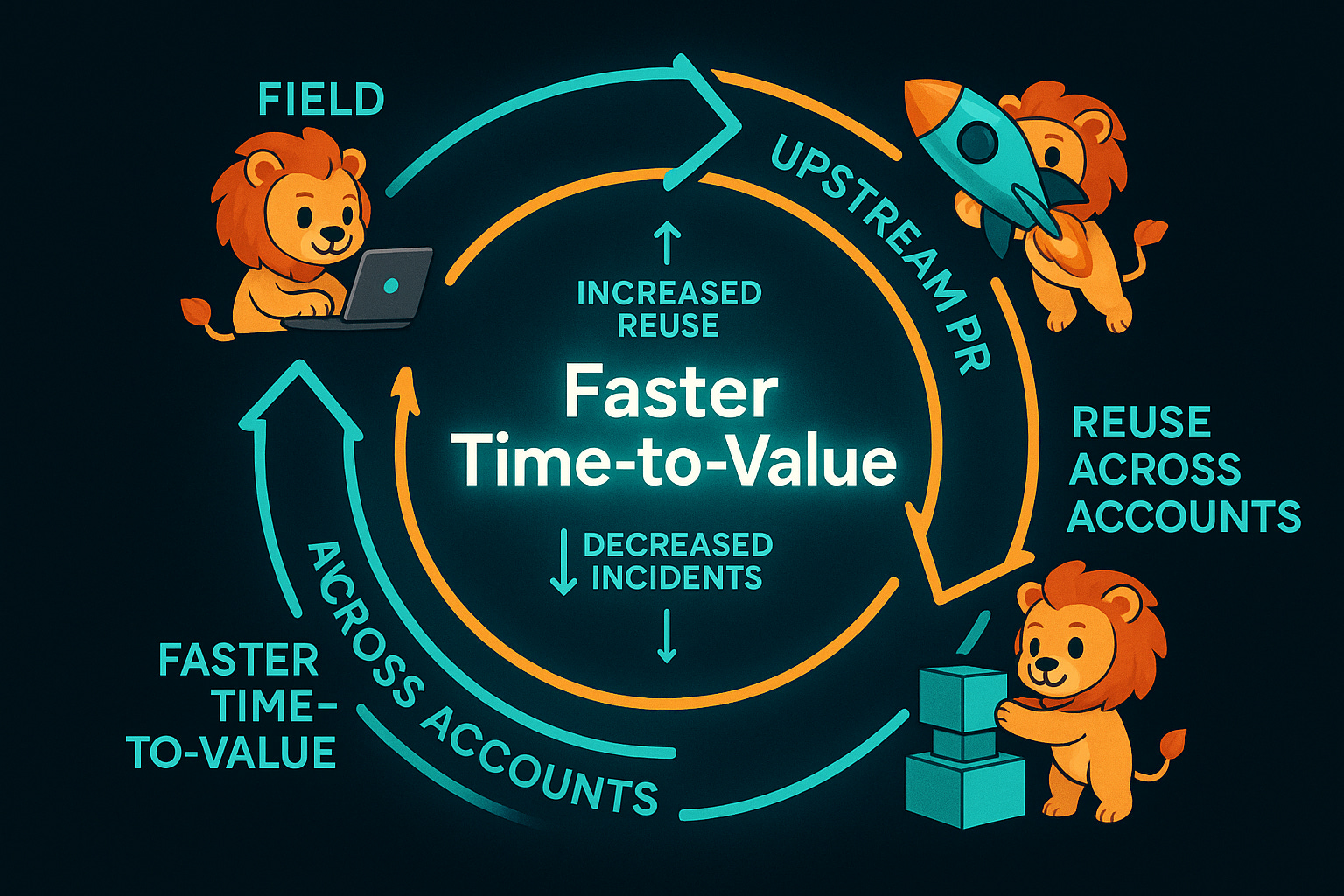
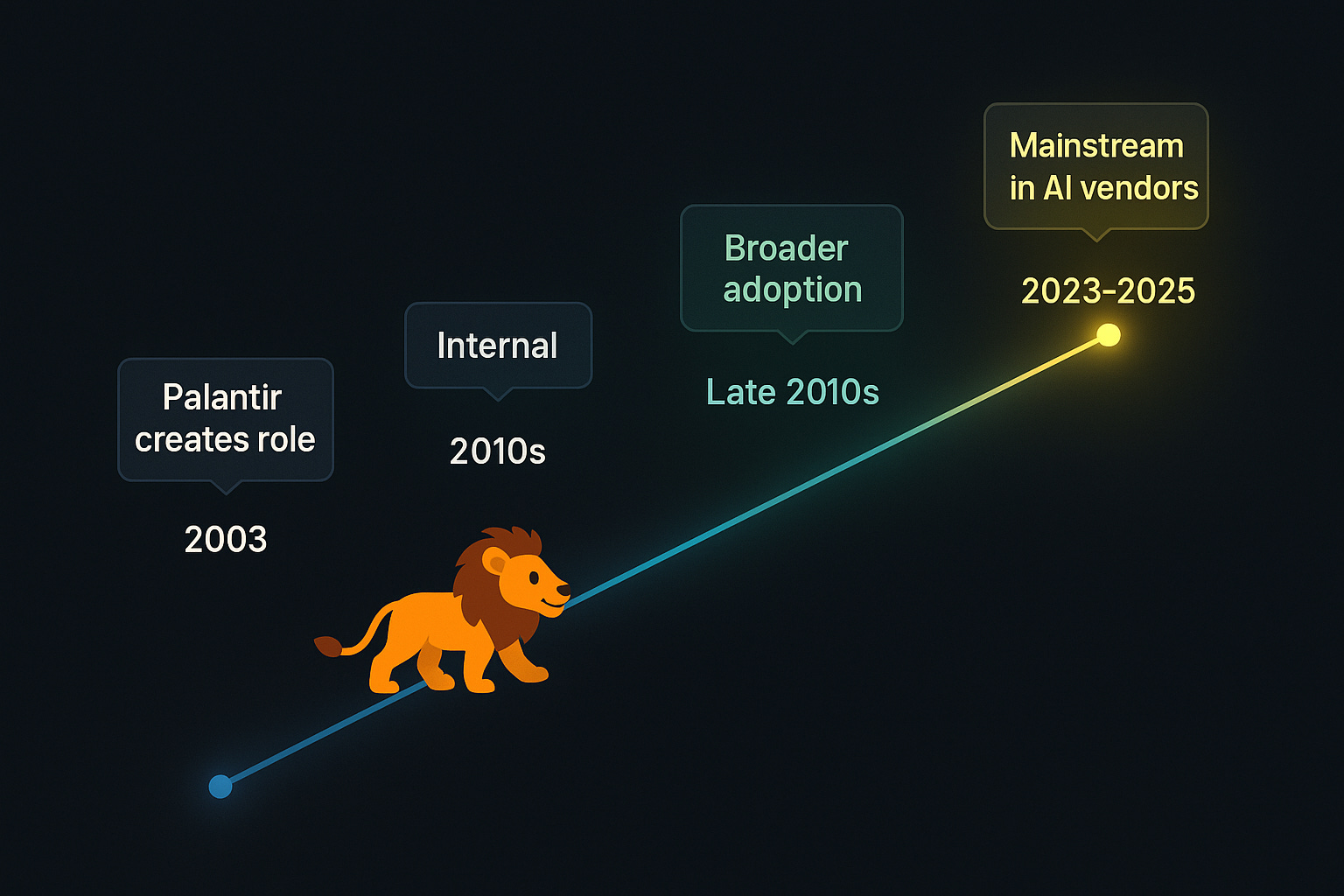
Current trend (2023–2025)
Origins at Palantir: Palantir created the forward‑deployed engineer role shortly after the company’s founding in 2003. These engineers were literally deployed at military sites and customer offices to work closely with users, understand their problems, and iterate quickly. For over a decad,e the role remained niche and specific to Palantir.
Proliferation: In the late 2010s, Scale AI and C3.ai adopted the title, and companies such as Databricks and Snowflake built similar functions to handle complex enterprise deployments.
Acceleration (2023–2025): By fall 2023, Ramp established its FDE team with two engineers. Within eighteen months, the team nearly 10× in size to 16 engineers and shifted from firefighting to building generalized features and AI platforms that improve time‑to‑value for enterprise accounts. AI vendors, such as OpenAI and Anthropic, now hire FDEs to bridge cutting‑edge models with operational realities.
Recognition: Today, the FDE function is recognized as essential for bringing advanced AI into production. A 2025 overview notes that Palantir’s forward‑deployed model became a blueprint adopted by leading AI companies like OpenAI and Anthropic to accelerate AI adoption in enterprises.
What an FDE is and does
An FDE is an engineer embedded directly with customers. Unlike traditional customer success or solutions roles, an FDE is deeply technical and empowered to:
Configure and adapt core software to real‑world environments. Palantir describes FDEs (which it calls Deltas) as engineers who deploy and customize platforms to tackle critical customer problems.
Diagnose and solve deployment challenges quickly. A Palantir FDSE working with the U.S. Department of Defense describes spending days monitoring, debugging, and configuring software on‑site.
Translate customer workflows into product feedback. FDSEs share technical expertise from the field back to product teams; some of Palantir’s most valuable product additions originated this way.
Co‑design data pipelines, integrations, and interfaces. Ramp’s FDEs build generalized features and AI that increase product‑market fit across new verticals such as healthcare and government.
Common practices
Immersion: FDEs spend time onsite or are deeply engaged with client workflows.
Customization: They adapt systems to customer‑specific infrastructure and constraints.
Feedback loops: Insights from the field flow back to core product and research teams, improving the platform for all customers.
Rapid iteration: They ship tailored solutions under tight timelines, often in mission‑critical contexts.
History at a glance
2003: Palantir is founded and creates the forward‑deployed engineer role for engineers literally deployed at customer sites.
2000s–2010s: The role remains mostly internal to Palantir; forward‑deployed engineers (“Deltas”) embed with operators and prioritize field fixes → upstream abstractions over long‑lived custom code.
Late 2010s: Scale AI, C3.ai, and Databricks adopt similar roles, seeing value in embedding engineers for complex enterprise deployments.
2023–2025: Ramp, OpenAI, and Anthropic build FDE teams; Ramp’s team grows from 2 to 16 engineers and shifts from firefighting to upstreaming generalized features. A 2025 guide notes that Palantir’s model has been adopted by leading AI companies to accelerate enterprise AI adoption.
Field‑learning pattern (Palantir 2003–2015)
Palantir’s early FDE teams embedded engineers with operators to observe real constraints such as data silos, air‑gapped networks, and adversarial users. They measured learning by the time from field bug to upstream fix and prioritized reuse. Engineers upstreamed fixes, documented reproducible cases, and retired bespoke code. As a result, time‑to‑value across new accounts decreased, and critical incidents post‑rollout were reduced.
Video evidence
The role of a Forward‑Deployed Software Engineer (Palantir, 2015)
Concisely shows the original FDSE pattern: engineers embedded with users’ own deployment success and convert field constraints into reusable product improvements. ▶️ Palantir: “The Role of a Forward Deployed Software Engineer” (00:55–01:32)
Anthropic in the Enterprise — applied AI deployment lessons (2025)
Illustrates how a modern AI vendor structures field evaluations, upstreams lessons to the core product, and avoids bespoke one‑offs. ▶️ Anthropic: “Anthropic in the Enterprise — Applied AI implementation strategies” (02:10–03:20)
First‑principles framework (FPF)
The following principles ensure that advanced technology is successfully deployed, adopted, and scaled in customer environments:
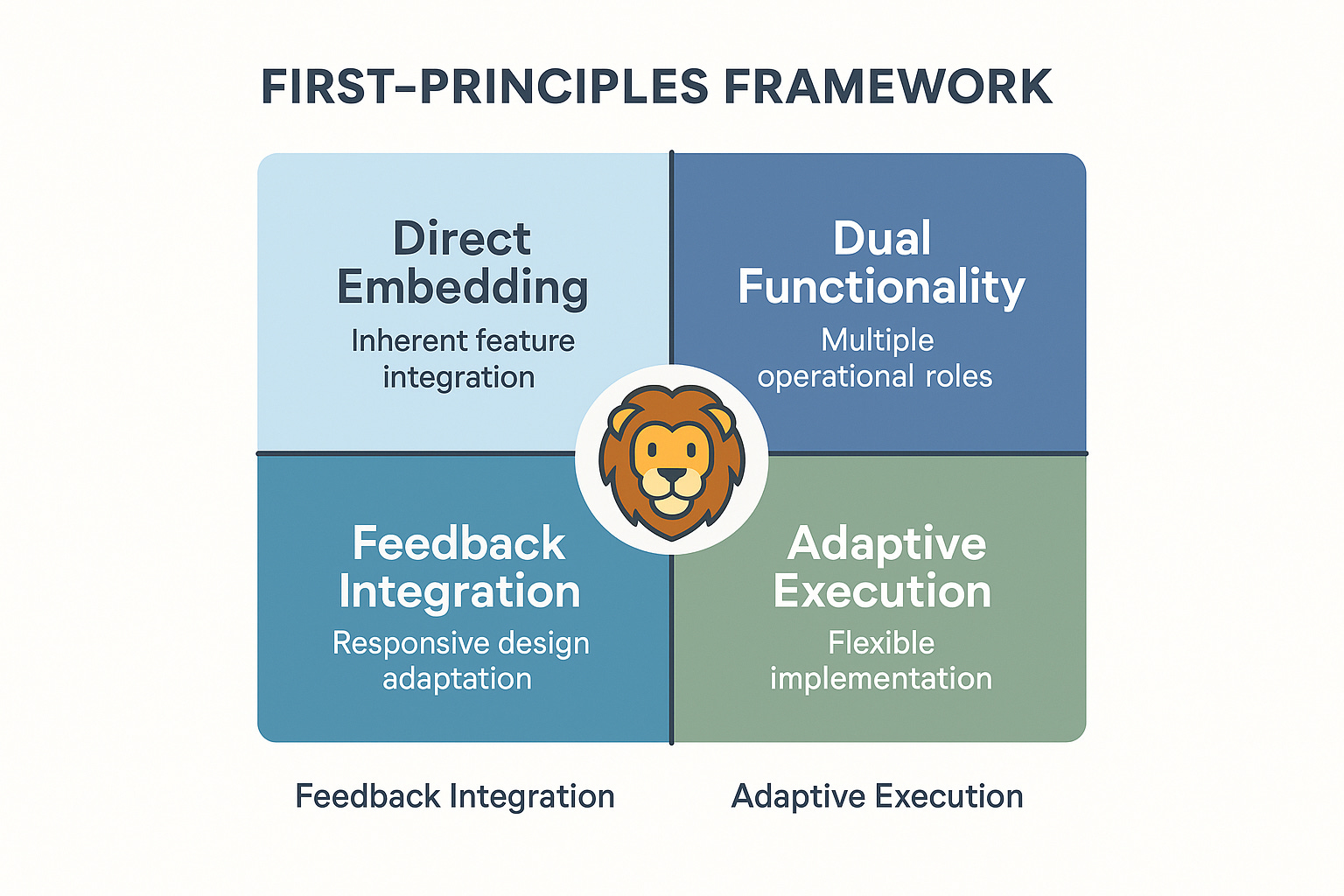
Direct embedding: Place engineers close to customer workflows to maximize context and minimize communication gaps.
Dual functionality: Combine technical problem‑solving with customer‑facing collaboration. FDEs must be able to write production code and build trust with non‑technical stakeholders.
Feedback integration: Treat every deployment as a source of structured product insight; field notes and upstream PRs are standard artifacts.
Adaptive execution: Prefer flexible, context‑sensitive solutions over rigid processes; FDEs thrive in ambiguity.
Derived practices
Co‑locate with customer teams to learn operational context.
Build rapid prototypes and integrations for real needs.
Translate between product engineers and business stakeholders.
Run short feedback cycles from field challenges to core updates.
Stay ready for high‑stakes, time‑sensitive incidents.

Operating system for FDEs
FDEs follow a repeatable cadence: Intake → Embed → Build → Generalize → Measure. Each stage has a clear objective and artifact.
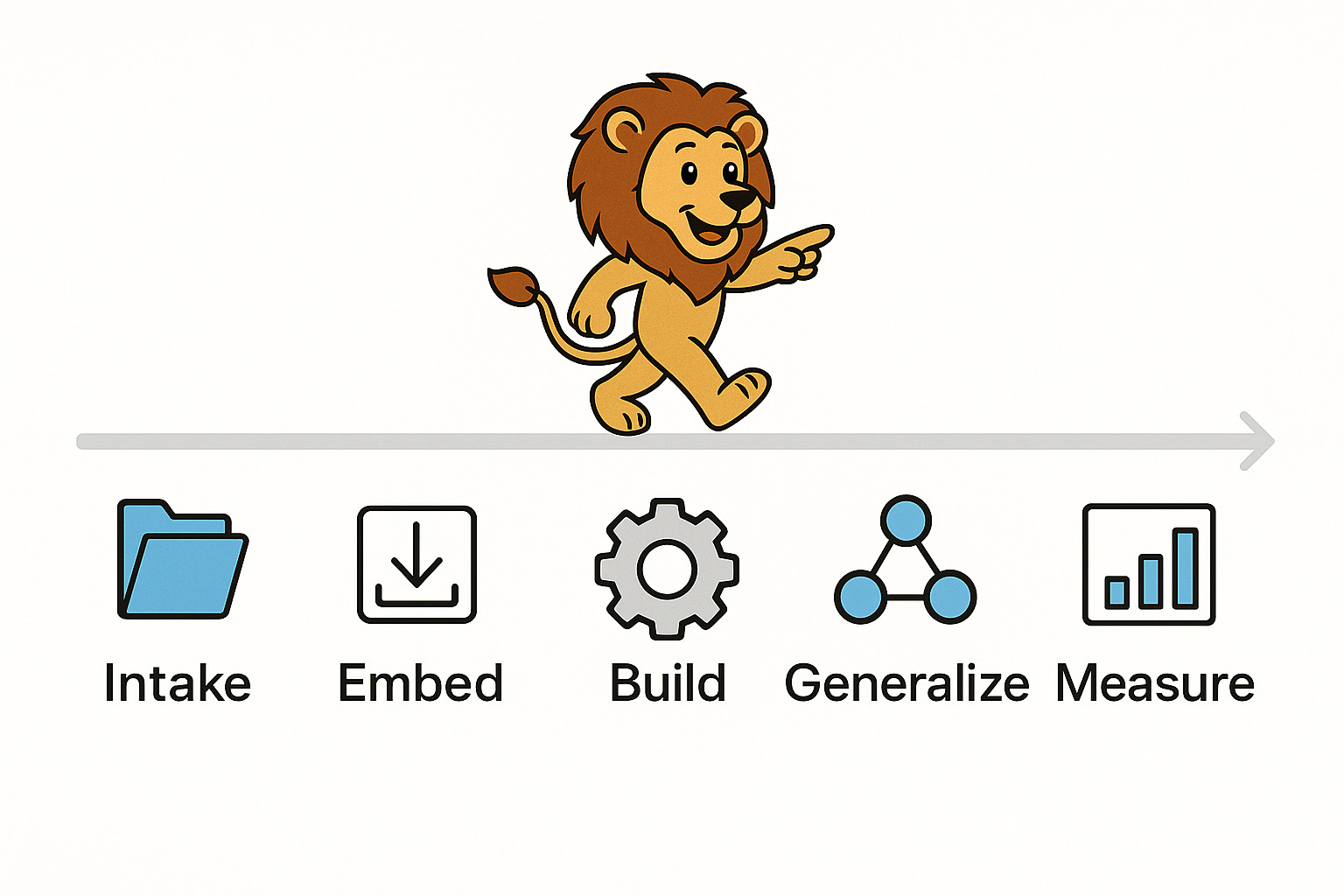
Weekly cadence
Intake: Qualify engagements with clear acceptance criteria and success metrics.
Embed: Pair with operators, map workflows, data, and constraints.
Build: Prototype the smallest slice that proves value end‑to‑end.
Generalize: Upstream abstractions and tests; retire local hacks.
Measure: Track time‑to‑value, incident,s and reuse across accounts.
Standard artifacts include the engagement brief (scope, risks, constraints), field notes (observations, hypotheses, testable predictions), demo narrative (user, task, definition of done,) and upstream PR template (customer context, reproducible case, tests).
Org design patterns
Team placement:
Product‑embedded FDEs are closer to roadmaps and releases; this is best for platform companies.
Field‑embedded FDEs are closer to revenue and executive sponsors; this is best for complex enterprise environments.
Ratios and interfaces: One FDE can typically handle two or three active enterprise accounts during rollout. They maintain a tight loop with Product and Core Engineering, and maintain structured handoffs with Solutions/Customer Success. Security and legal reviews are front‑loaded during discovery.
Metrics that matter
Successful FDE teams measure both outcomes and leading indicators:
Outcomes: reduced time‑to‑value and time‑to‑first‑PR; higher share of field‑originated product changes shipped per release; fewer critical incidents after rollout.
Leading indicators: median time from field bug to upstream fix; number of reusable modules per engagement; coverage (percentage of deployments using upstreamed components).
Ramp FDE references
The Ramp Builders blog explains that FDE at Ramp started in fall 2023 and, within about a year and a half, grew from two to sixteen engineers, allowing the team to shift from firefighting to upstreaming generalized features and AI platforms.3
Ramp’s FDE team now focuses on building reusable platforms and AI across pods to reach product‑market fit faster in new segments such as healthcare and government.3
Anti‑patterns to avoid
Long‑lived custom code with no upstream PR.
Hero engineers as single points of failure.
Shadow roadmaps driven by deal pressure.
FDEs acting as permanent “PMs of last resort.”
Close
If your deployments feel like Groundhog Day, you don’t need more demos—you need a faster error‑correction loop with reality. Staff it with forward‑deployed engineers and measure the learning rate, not the slide count. The field‑to‑product flywheel isn’t magic; it’s a discipline of embedding, upstreaming, and learning that turns customer pain into product advantage.